
만족
[Linux Kernel] Kernel Linked List 본문
[Linux Kernel] Kernel Linked List
기타 CS 이론/Kernel Satisfaction 2021. 3. 28. 22:00리눅스 커널에서는 자체적으로 LinkedList를 제공한다.
여기에서 제공되는 LinkedList는 "원형 더블 링크드 리스트이다"
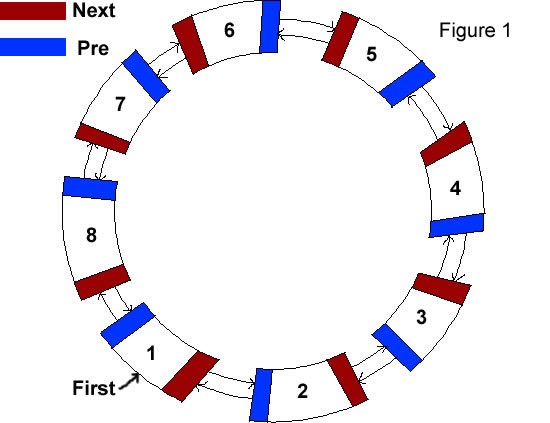
이...이게뭐노..?
이미지에서 볼 수 있듯이 각 노드는 head와 prev 포인터를 갖는다.
//#include <linux/list.h>
struct list_head{
struct list_head *prev, *next;
}엥? 각 노드에 데이터는 어디있나?
특이하게도 prev, next, data가 평면적으로 존재하는것이 아니라,
data안에 prev,next 정보를 가진 구조체 변수가 존재한다.
struct your_data{
struct list_head list;
int data;
}그러니까 위의 Circular Doubly Linked List에서 각 노드마다 data가 같이 존재하는게 아니라,
실제 이 자료구조를 조작하는 데는 prev, next만 가지고 이루어진다는 말이다.

즉, 다시 말해 각각의 list_head는 데이터가 어디 있는지는 관심이 없고 지들(list_head)끼리 엮여있을 뿐이다.
이제 이걸 사용해보자.
초기화
//list 내에는 head,prev 포인터가 있다.
struct simple_list{
struct list_head list;
int id;
};
struct simple_list myList;
//...
//myList 내부의 list멤버의 주소값을 전달하여 해당 list값을 초기화한다
//이 때 list.head, list.prev는 자기 자신을 가리킨다.
INIT_LIST_HEAD(&myList.list);INIT_LIST_HEAD();를 사용한다.
데이터 삽입
struct simple_list *temp= NULL;
unsigned int i;
INIT_LIST_HEAD(&myList.list);
for(i= 0; i<5; i++){
temp= (struct simple_list*)kmalloc(sizeof(struct simple_list), GFP_KERNEL);
temp->id= i;
printk("simple_linked_list: add to list [%d]\n", temp->id);
list_add(&temp->list, &myList.list);
}첫 번째 줄인 struct simple_list* temp에는 반복마다 임시로 쓸 변수다.
for문을 보면 kmalloc을 쓰는데, 일반 App개발이 아닌 kernel 내에서 작동할 프로그램이기 때문에
vmalloc 또는 kmalloc을 쓴다.
사용법은 malloc과 비슷하니 잘 모르겠다면 malloc이라고 생각하고 봐도 된다.
암튼 새로운 데이터를 생성하고,
list에 해당 데이터를 추가하기 위해서 list_add()를 쓴다.
list_add의 첫 번째 매개변수는 생성한 데이터의 list 멤버의 주솟값이다.
이걸 알려줘야 추가될 데이터 내부에 있는 list(head, prev 정보가 있는 곳)에
데이터가 삽입되고 나서 head,prev 정보를 올바르게 지정할 수 있다.
list_add의 두 번째 매개변수는 LinkedList의 head의 list 멤버의 주솟값이다.
이것 역시 알려줘야만 원본 List에 올바르게 추가할 수 있다.
다시 말하지만, list_add에서 봤듯이, 이 LinkedList는 데이터가 어디에 있는지는 관심이 없다.
오직 list_head가 어디있는지, 각각의 list_head가 어떻게 연결되어 있는 지에만 관심이 있다.
데이터 순회
struct simple_list *temp= NULL;
struct list_head* pos= NULL;
unsigned int i= 0;
list_for_each(pos, &myList.list){
temp= list_entry(pos, struct simple_list, list);
printk("simple_linked_list: pos[%d] => id=%d\n", i, temp->id);
i++;
}데이터 순회는 list_for_each(){}로 한다.
이..이...이게뭐노...?
이걸 처음 보고는 좀 벙쪘는데, list_for_each는 일반 함수가 아니다.
매크로 함수로 작성되어 프리프로세싱 단계를 거치면 for문으로 변환된다.
조건은 list의 시작점부터 next, next ... 하다가 next가 시작점을 다시 가리킬때 까지 반복한다.
(Circular 속성을 가졌기 때문이다)
매개변수로는 현재 list_head의 포인터(pos)와 list_head포인터를 받으며,
매 순회마다 pos값이 변한다.
즉, 입력받은 list_head 포인터를 기준으로 한 번의 순회가 끝날 때 마다
그 list의 next로 이동하여 다시 순회하는것을 반복한다.
내부를 보면 다시 list_entry()를 사용하는 것을 볼 수 있는데,
우리가 list_for_each에서 받아온 데이터는 pos(list_head 포인터) 뿐이기 때문에
실제 해당 노드의 데이터(struct simple_list 타입)가 어디있는지는 list_entry를 통해 구해야만 한다.
list_entry역시 매크로 함수이기 때문에 일반 함수와는 다르게 생겼다.
list_entry는
"현재 노드의 list_head 포인터,
현재 노드의 list_head를 포함하는 구조체의 타입,
그 구조체 내부에서 list_head 구조체의 멤버 변수 이름"
이라는 3개의 매개변수를 받는다.
자 다시 list_head를 포함하는 simple_list 구조체의 형태를 보자.
//list 내에는 head,prev 포인터가 있다.
struct simple_list{
struct list_head list;
int id;
};이걸 기준으로 봤을 때, list_entry의 용례는 다음과 같다.
struct list_head* pos= NULL;
list_entry(pos, struct simple_list, list);이 다음부터는 얻어온 데이터를 사용하면 된다.
list_entry의 원리
그런데 "어떻게 이 정보들을 가지고 simple_list를 역추적할 수 있는 건지" 궁금해진다.
짧게 설명하자면, struct 내부에 선언된 멤버들은 컴파일 타임에 동일한 패턴으로 메모리에 쌓인다.
그 말은 즉, 컴파일이 완료되면
simple_list 내부에 있는 list와 id가 기준점으로부터 얼마만큼 떨어져 있는지 알 수 있다는 것이다.
예를 들어 struct simple_list test; 가 x번지부터 시작한다고 하면,
test.list는 x+a 주소에 있을 것이고
test.id는 x+b 주소에 있을 것이다.
(a, b는 모두 상수이다. struct simple_list test2; 를 선언한다고 해도 x만 변할 뿐 a, b는 같다.)
그런데 우리는 pos 포인터를 알고 있으므로, x+a의 값을 알게 되었다.
(x+a는 해당 구조체 내부의 list값의 주솟값. 즉 pos와 동일한 주소값이다; pos== x+a)
또한 a도 컴파일 타임에 이미 특정 값으로 결정되었다.
따라서, x의 위치(x== pos-a), 즉 데이터의 포인터를 구할 수 있게 되는 것이다.
이제 list_entry가 해당 list_head를 포함하는 구조체의 포인터를 어떻게 리턴하는지 알았다.
데이터 제거
struct simple_list *temp= 0;
struct list_head* pos= 0;
struct list_head *q= 0;
unsigned int i= 0;
list_for_each_safe(pos, q, &myList.list){
temp= list_entry(pos, struct simple_list, list);
printk("simple_linkled_list: free pos[%d] => id=%d", i, temp->id);
list_del(pos);
kfree(temp);
i++;
}데이터 제거를 위한 순회에는 list_for_each가 아닌 list_for_each_safe를 사용한다.
왜냐면, list_for_each에서 순회에 사용하는 변수는 현재 위치의 list_head 포인터 뿐인데,
여기서 현재 노드를 지워버리면 next, prev 정보를 알 수 없게 된다.
반면 list_for_each_safe에서는 미리 next 포인터 정보를 가져옴으로써 현재 노드인 pos를 삭제하더라도 순회하는데 문제가 없어진다.
마찬가지로 list_entry()를 사용해 데이터의 포인터를 얻어올 수 있으며,
만약 삭제를 원하는 경우 list_del()에 현재 list_head의 포인터를 전달함으로써 리스트에서 삭제할 수 있다.
삭제한 후, 필요한 경우엔 kfree()를 사용해 아까 kmalloc()으로 할당받은 메모리를 해제할 수도 있다.
===============
역시 C언어는 하드코어하다...
'기타 CS 이론 > Kernel' 카테고리의 다른 글
| [Linux Kernel] Real-Time CPU Scheduling (0) | 2021.06.15 |
|---|---|
| [Linux Kernel] Deferrable Functions (0) | 2021.06.15 |
| [Linux Kernel] RCU (Read-Copy Update) (0) | 2021.06.15 |
| [Linux Kernel] Interrupt (0) | 2021.06.15 |


