[MongoDB] CPU Spike(frequently high load) 문제
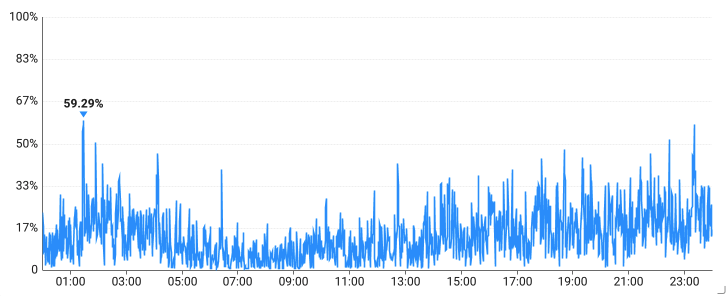
서버에서 MongoDB를 사용한 이후 별로 무거운 작업이 없음에도 CPU 로드율이 미친듯이 날뛰는 문제가 포착되었다.
MongoDB를 사용하기 이전에는 볼 수 없었던 문제인데다,
쿼리들 역시 단순히 특정 컬럼을 하나 찝어 일치하는 row 하나를 불러오는 아주 간단한 작업이였기 때문에 어떤 이유로 저런 그래프가 그려지는지 궁금해졌다.
해당 문제에 대해 조사하던 중, 크게 세 가지 원인이 있음을 알아냈다.
1. 거대한 Log 사이즈
mongodb는 기본적으로 /var/log/mongodb/mongod.log 에 로그를 저장한다.
그런데 해당 로그 사이즈가 너무 거대해질 경우(GB단위 이상) 성능에 큰 영향을 끼친다고 한다.
cd /var/log/mongodb로 로그파일이 있는 경로로 이동하고,
ls -al로 해당 폴더 내의 로그 파일 크기를 알아낸다.
drwxr-xr-x 2 mongodb mongodb 4096 Dec 18 00:55 .
drwxrwxr-x 10 root syslog 4096 Dec 28 06:25 ..
-rw------- 1 mongodb mongodb 66312355 Dec 28 15:43 mongod.log내 서버의 mongodb로그는 약 66MB로 걱정할 것이 없는 수준이다.
만약 GB단위를 넘어섰다면, 파일명을 변경하거나 파일을 삭제해서 새로운 파일에 로그가 쓰여지게 하면 된다.
2. Slow Query
특정 쿼리가 오래 걸려 DB를 점유하고 있는 경우에는 그 쿼리가 뭔지 파악해야 한다.
mongo먼저 mongo 명령어를 이용해 mongo shell로 진입힌다.
db.currentOP()진입 후 위의 명령을 이용해 현재 실행되고 있는 쿼리의 정보를 알아낼 수 있다.
CPU spike가 찍힌 지점에서 실행해 보면 어떤 쿼리가 실행 시간을 많이 잡아먹고 있는지 파악할 수 있으므로,
해당 쿼리를 최적화하면 된다.
3. Non-Indexed Document
mongodb는 document에 기본 index key를 지정하지 않으면 _id라는 컬럼을 index로 지정한다.
그러나 mongoose(nodejs)와 같은 라이브러리를 활용하여 mongodb를 제어하는 경우 index가 없는 상태로 사용될 수 있다.
index에 대해 깊게 설명하진 않을 테지만, 우선은 없으면 read 속도가 매우 떨어지고 CPU 부하가 심해진다는 점을 알아두자.
mongoose에서는 스키마 정의 방법을 다음과 같이 정해 두었다.
const cacheSchema = new Schema(
{
key: String,
data: Object,
cacheDate: {
type: Date,
default: Date.now
}
}
);그런데 해당 스키마에는 index가 없다.
실제로 mongoose문서의 처음을 보면 index를 지정하는 부분이 빠져있다.
이대로 가져다 쓰면 나처럼 무수한 CPU Spike를 맞이하게 되는 것이다.
따라서 다음과 같이 index를 지정해야 한다.
const cacheSchema = new Schema(
{
key: {
type: String,
index: true
},
data: Object,
cacheDate: {
type: Date,
default: Date.now
}
}
);(key값을 index로 사용한다)
나의 경우에는 이것이 가장 크리티컬한 문제였기 때문에 index를 지정해 주자 바로 문제가 해결되었다.
Connection pool
사용자가 증가함에 따라 다시 문제가 발생했다.
mongoose 공식 문서를 읽어보던 중, connection pool 파트에서 해결책을 알아냈다.
mongoosejs.com/docs/connections.html#connection_pools
Mongoose v5.11.11: Connecting to MongoDB
You can connect to MongoDB with the mongoose.connect() method. mongoose.connect('mongodb://localhost:27017/myapp', {useNewUrlParser: true}); This is the minimum needed to connect the myapp database running locally on the default port (27017). If connecting
mongoosejs.com
// poolSize에 최대 커넥션 갯수를 명시한다
mongoose.createConnection(uri, { poolSize: 20 });
mongoose의 기본 커넥션 풀 사이즈는 5개인데,
사용자가 몰려 커넥션이 부족한 상태가 되면 속도가 매우 느려진다.
(가령 100명의 사용자가 동시에 mongodb와 통신하는 요청을 보내는 경우)
스레드 풀은 간단히 말해서 '차선 갯수'와 같다고 보면 된다.
차가 매우 많은데, 도로가 1차선이라면 매우 막힐 것이다.
이걸 5차선, 10차선으로 뚫어주는게 '커넥션 풀'의 역할이라고 보면 된다.
그런데 커넥션이 모자라게 되면 오히려 해당 프로세스가 Block상태가 되어 연결이 성립될 때 까지 대기하므로
오히려 로드율은 낮은데 속도가 느려지는 것으로 알고 있는데,
왜 CPU load가 치솟았는지는 아직 잘 모르겠다.
뭐... 고쳤으면 된건가...