[사이퍼즈 서포터] 헬스체크 정책 추가
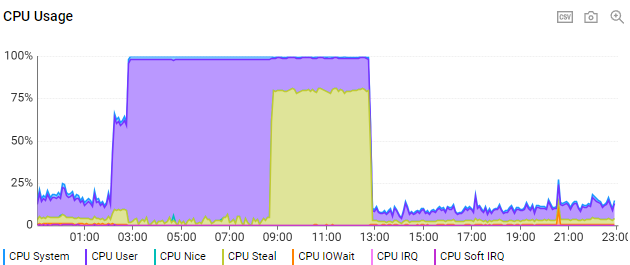
얼마 전부터, 불명의 원인으로 서버의 CPU수치가 100%로 치솟으면서 내려오지 않아 서버가 요청을 전혀 처리하지 못하는 현상이 발생하고 있다.
특정 프로세스, 특정 시간이나 특정 주기로 발현되는 증상도 아니고,
어쩔 땐 하루에 두번이나 저랬다가 또 어쩔 땐 몇주동안 발생하지 않는다.
아직 원인을 찾지 못해서 장애를 인지하면 문제가 되는 프로세스를 재시작하고 있다.

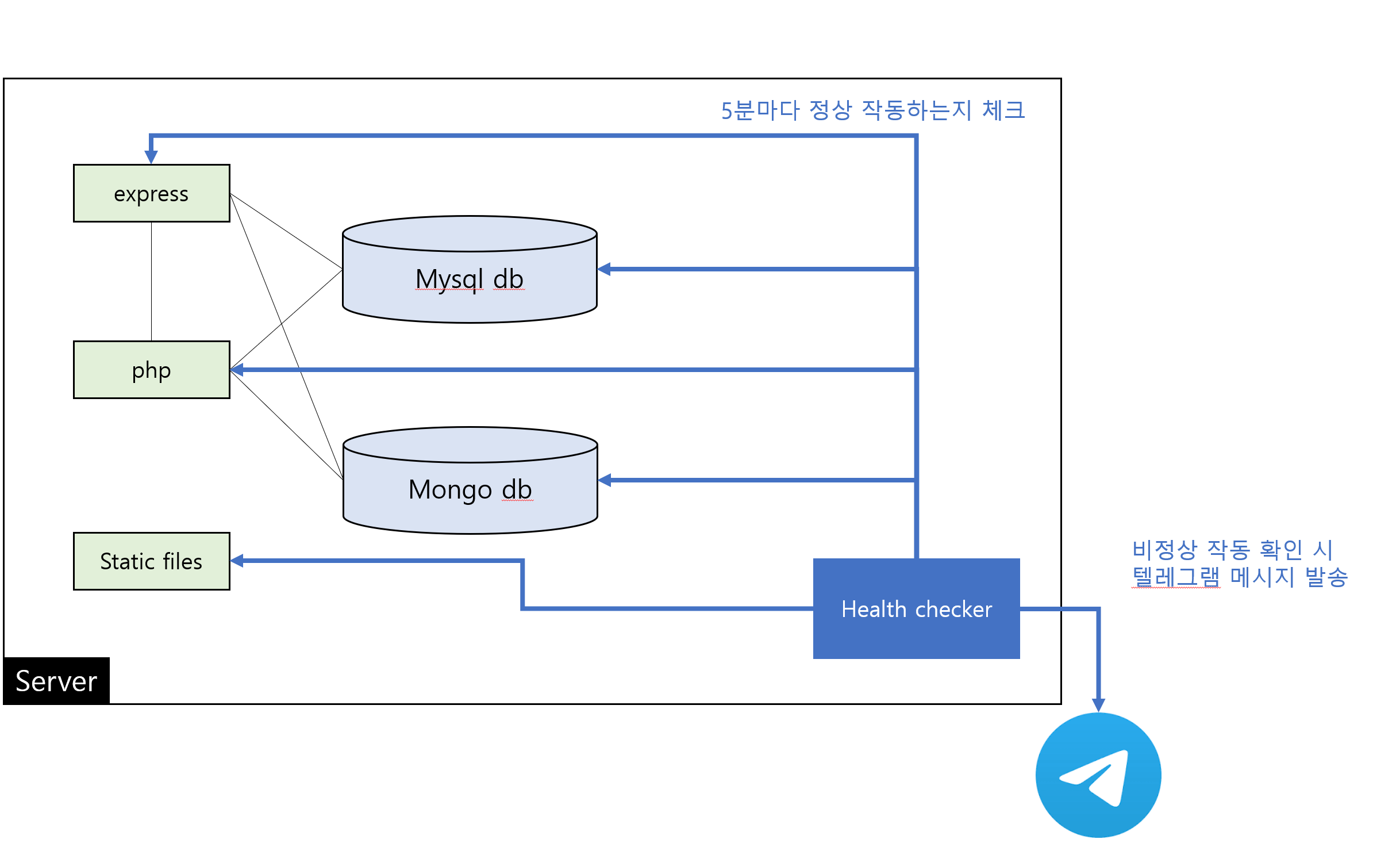
현재 서버 내 서비스 구조를 간단히 요약하면 위와 같다.
백엔드 프레임워크들끼리도 특정 기능을 의존하고 있고,
DB는 거의 모든 api에서 사용하고 있기 때문에 이들 중 하나만 장애가 발생하더라도 연쇄적으로 장애가 발생한다.
장애가 발생할 경우 빠른 인지, 수정, 복구가 가능해야 하는데, 이 상황에서 가장 중요한 것은 '빠른 인지'기 때문에
나의 니즈에 맞는 모니터링 프로그램이 필수적이다.
따라서 이 기능들이 잘 동작하고 있는지 주기적으로 체크해서,
문제가 발생하면 텔레그램 메시지를 발송하도록 하는 모니터링 도구를 추가했다.
예를 들어 db 헬스체크는 커넥션을 받아와 'SELECT 1' 과 같은 더미 쿼리가 동작하는지 확인하고,
api server 헬스체크는 서버가 정상 동작 중이라면 200을 리턴하는 엔드포인트를 추가하여 확인하는 것이다.
물론 '다운' 상태만 장애로 판단하는 것이 아닌 '원활한 상태'가 아닌 경우 모두 장애상황으로 판단해야 하기 때문에 타임아웃 수치는 비교적 짧게 주었다.
별거 아니지만 이렇게 함으로써 하나 이상의 서비스가 다운되었을 때 직접 들어가보지 않더라도
기존보다 훨씬 빠르고 정확하게 어떤 서비스에 장애가 생겼는지 알아차릴 수 있게 되었다.
그러나 여전히 모든 기능이 서버 하나에 집중되어 있기 때문에
Server 자체가 다운되거나 마비되어 매우 느리게 동작한다면 직접 접속해보지 않는 한 알아낼 방법이 없다.
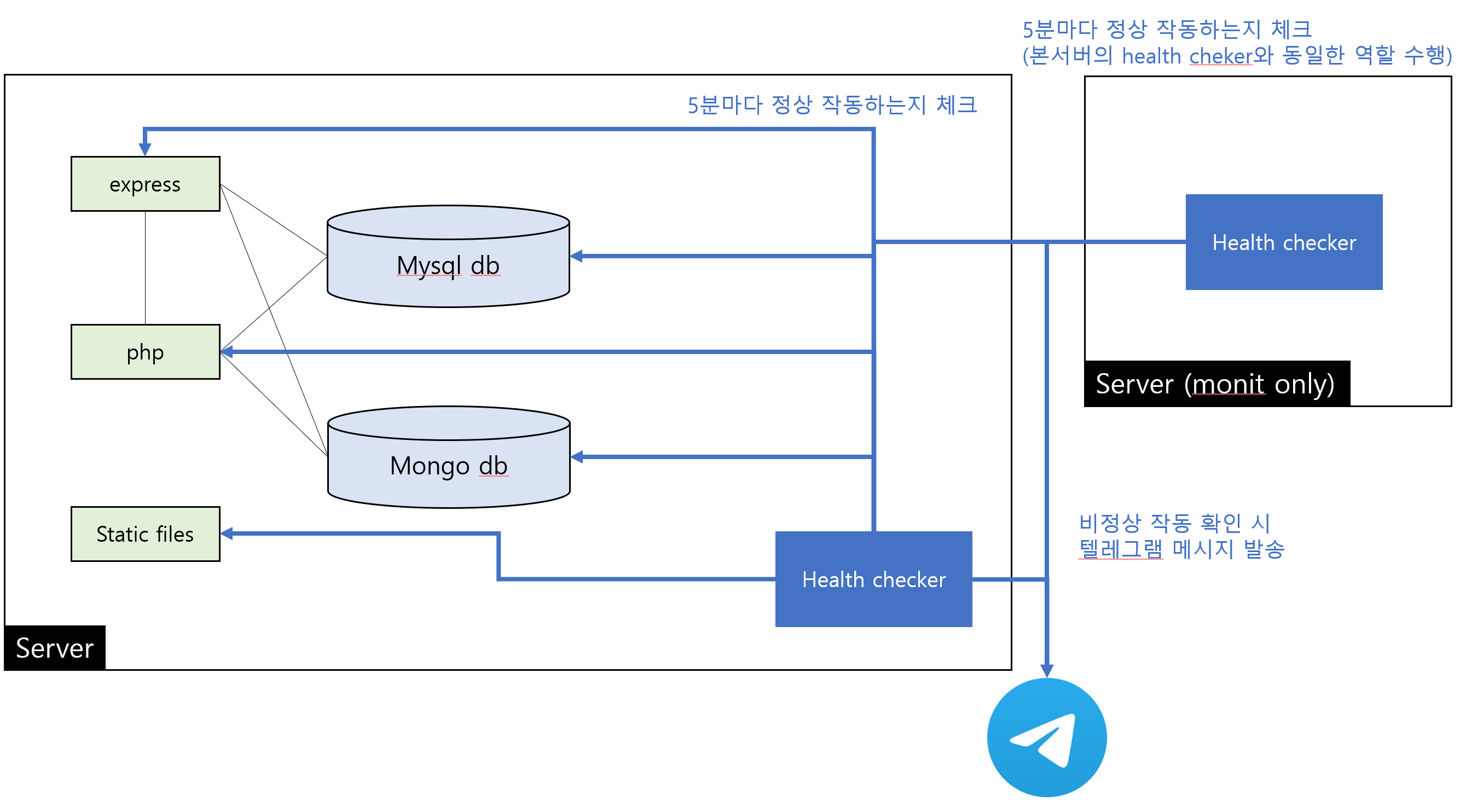
그래서 사양이 낮은 서버를 새로 생성하여, 기존 서버에서 하던 health check를 동일하게 해 두었다.
이렇게 되면 모니터링 전용 서버와 서비스 서버가 동시에 다운되지 않는 이상 서비스 장애를 빠르게 인지할 수 있게 된다.
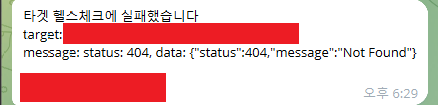
만약 api server에서 404가 나올 수 없는 지점에서 발생한다면 텔레그램으로 위와 같은 알람이 오게 된다.
해결하기 전까지는 5분마다 계속 알람이 가므로 피곤해서 기절하지 않는 이상 빠르게 대응할 수 있게 되었다.