
만족
[데이터사이언스] Regression (회귀) 본문
[데이터사이언스] Regression (회귀)
데이터사이언스 Satisfaction 2021. 10. 22. 10:54Deterministic Model (결정적 모델)
변수 간 관계가 명확하여 무작위성이 주는 영향이 없거나 미미한 경우
BMI지수를 계산할 때
BMI= 몸무게/(키^2) 로 계산한다.
=>몸무게와 키 정보가 주어지면 정확하게 BMI값을 계산해낼 수 있다.
=>무작위성이 없다
Probablistic Model (확률론적 모델)
무작위성이 존재하며 확률론적 모델은 결정적 모델과 오차(Random Error)가 합쳐져 구성된다.
수축기혈압을 계산할 때의 공식은 다음과 같다.
SBP= 6* age+ ε (ε은 오차)
=> 수축기혈압은 나이와 연관이 있지만, 동일한 나이를 가진 사람 전부가 동일한 수축기혈압을 가지지는 않는다
=> 20살인 어떤 사람은 SBP가 123일수도, 117일수도 있다.
오차 ε는 명시된 변수 외에 영향을 미치는 알 수 없는 변수에 의한 오차를 보정한다.
(SBP는 나이 외에도 지병이나 체중 등에 의해 영향을 받을 수도 있다)
Regression Model (회귀 모델)
확률론적 모델을 생성할 때 Regression Model을 이용할 수 있다.
Regression은 특히 예측이나 평가에 주로 사용된다.
Regression Model의 간단한 예를 하나 들겠다.
내가 달리기를 매일 한다고 해 보자.
1년차에는 100m 달리기를 15초에 기록하고,
2년차에는 100m달리기를 14초에 기록하고,
3년차에는 100m달리기를 13초에 기록했다고 해 보자.
그렇다면 4년차에 내 100m달리기 기록은 12초가 될 것이라고 추측해볼 수 있다.
물론 실제로 4년차에 그대로 13초일 수도 있고 11초가 될 지도 모르지만,
이처럼 알려져 있는 데이터를 통해 알려지지 않은 독립변수값에 의한 의존변수값을 통계적으로 계산하는 방법이 regression이다.
Simple Linear Regression
Simple은 독립변수가 1개,
Linear는 얻어낸 equation이 직선 형태, 즉 1차식인 것을 의미한다.
따라서 Simple Linear Regression은 1개의 독립변수(x)에 대해
일차식 형태의 방정식을 이용해 의존변수(y)값을 예측하는 모델이다.
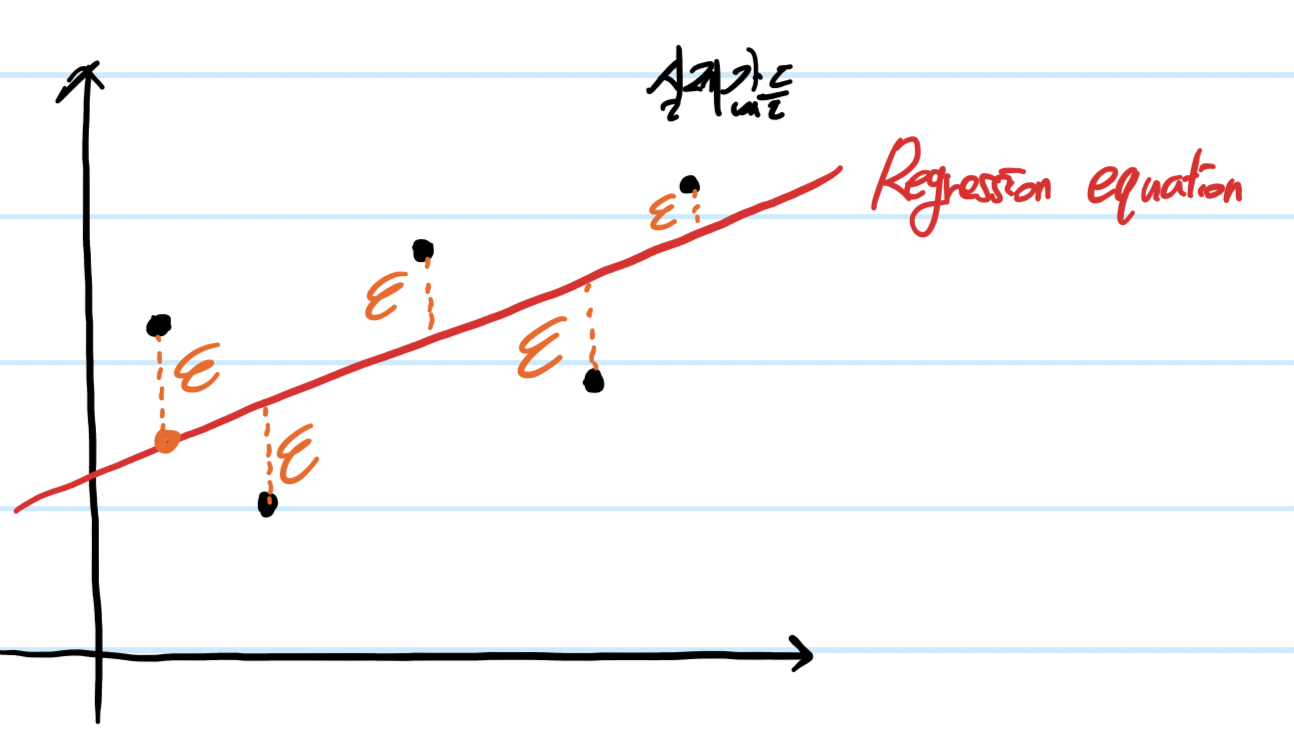
위와 같이 실제 값과 완전히 동일하지는 않지만 독립변수의 변화에 따른 의존변수의 변화 경향성을 확인할 수 있는 방정식을 구할 수 있다.
그렇다면 이제 실제로 이 방정식(모델)을 구해보도록 하자.
먼저 실제값에 대해 방정식을 세워보자.
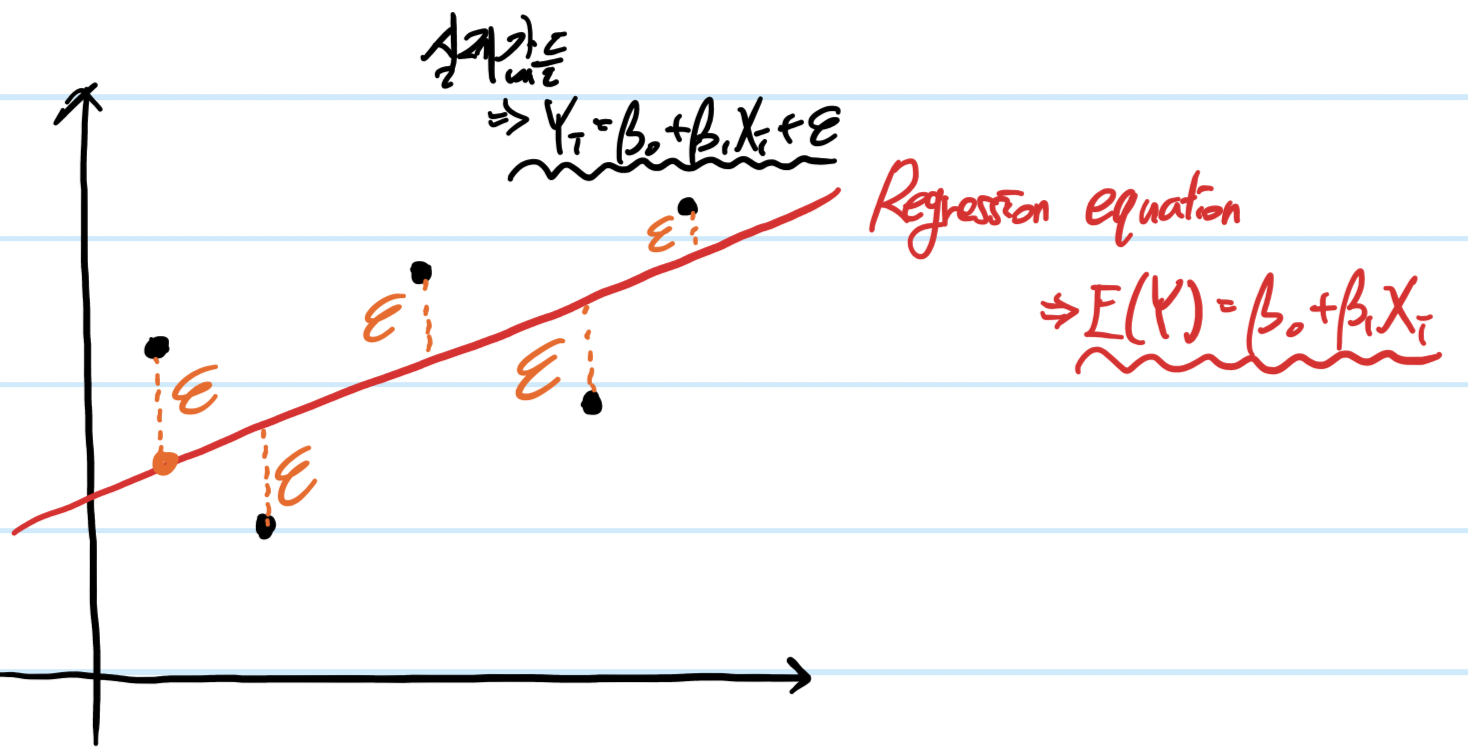
위 그림에서 실제 결과값(Y)는 아래 식으로 정의된다.
Yi= β0+ β1*Xi+ ε (단 Yi, Xi는 i번째 실제 Y,X값이고 ε는 오차)
(1차식에서 위 그래프의 모든 점을 지나게 할 수는 없으므로 ε를 통해 보정한다)
Yi뭐시기뭐시기...
이렇게 보니까 머리가 띵해진다.
그러나 기호만 좀 복잡해졌을 뿐, 우리가 중학생때 배웠던 일차방정식의 개념과 완전히 동일하다.
y= ax+b
여기서 오차 ε를 잠시 제쳐두면 y= ax+b에서a는 β1, b는 β0가 된다.
이제 회귀를 통해 예측 방정식(모델)을 만들어 보자.
Predict(Yi)= β0+ β1* Xi
(단 Predict(Y)는 예측된 Y값)
예측 모델은 위와 같다.
예측 모델은 독립변수에 따른 의존변수의 변화 경향성을 파악하기 위해 사용하므로
오차ε는 사용하지 않는다.
Yi= β0+ β1*Xi+ ε (단 Yi, Xi는 i번째 실제 Y,X값이고 ε는 오차)
Predict(Yi)= β0+ β1* Xi (단 Predict(Y)는 예측된 Y값; 그림에서는 E로 표현했으나 평균을 의미하는 것이 아니다)
이제 실제값들과 회귀모델의 방정식을 위와 같이 쓸 수 있다.
Population vs Sample Linear Regression
전체 모집단에 대해 regression했을 때와
일부 표본집단에 대해 regression 했을 때의 모델은 다르게 나타날 수 있다.
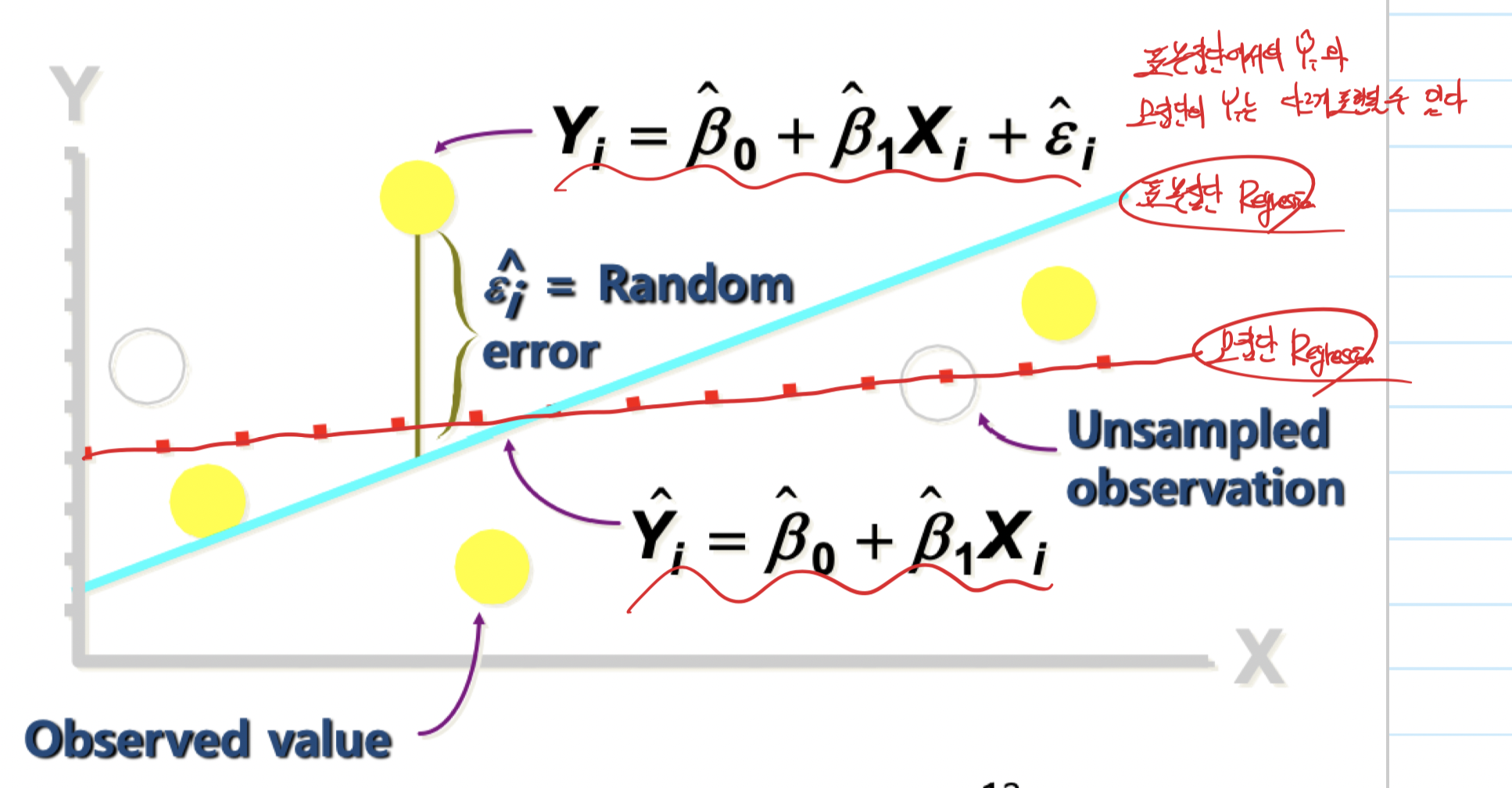
게다가 현실에서 모든 데이터를 얻어내는 것은 거의 불가능하다.
애초에 그런 경우에는 예측 없이 그냥 값을 구할 수 있다.
(모든 x,y쌍이 알려져 있다면 그냥 찾기만 하면 된다)
따라서 표본집단이 모집단과 유사해야만 한다.
이는 표본의 갯수가 충분히 크다면, 모집단과 유사한 결과를 얻을 수 있다는 대수법칙을 통해 극복할 수 있다.
Simple Linear Regression: find best fit
Regression이 어떤 원리를 가지는지, 어떻게 모집단과 유사하게 만들 수 있는지를 알았다.
그렇다면 이제는 어떻게 해야 가장 최적의 예측 모델을 만들어낼지를 고민해보자.
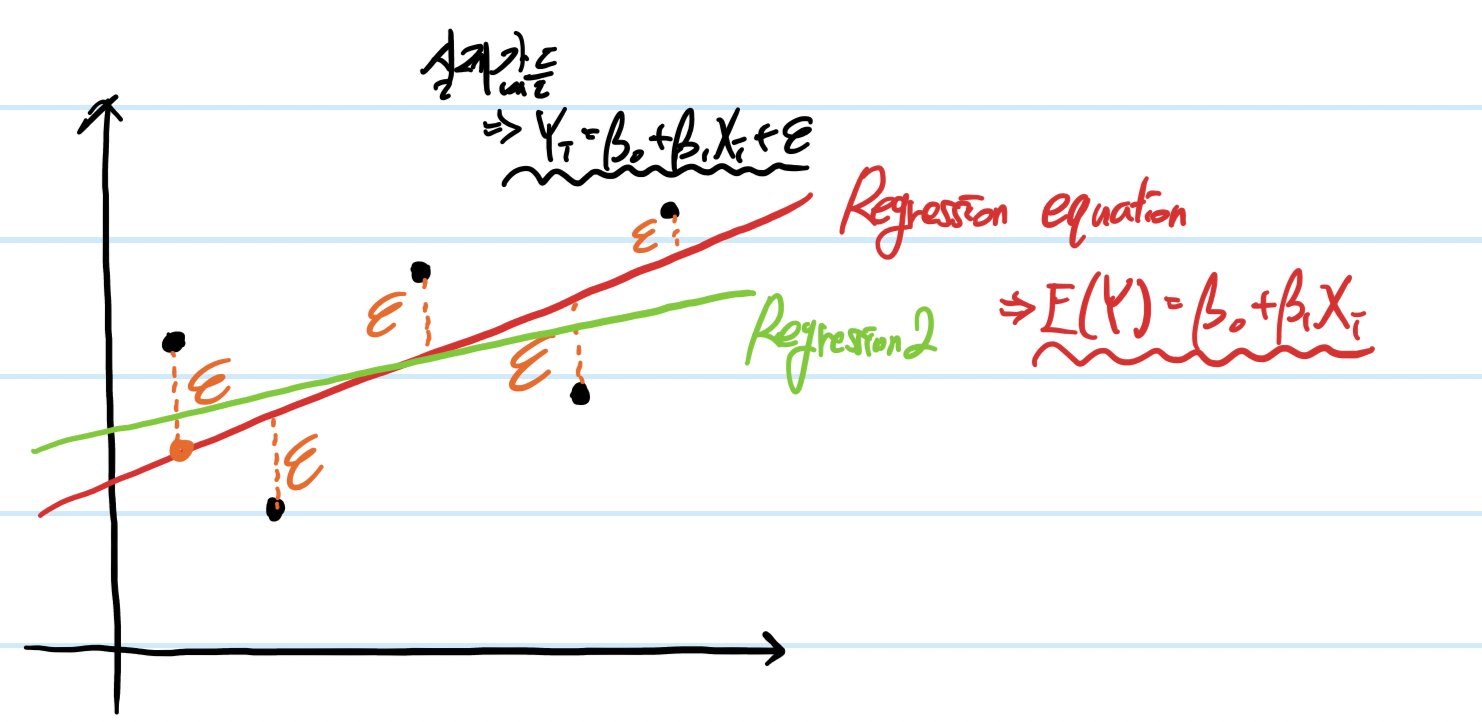
이처럼 다른 모양으로 regression을 그려낼 수도 있다(초록색).
그렇다면 붉은색과 초록색 중 어떤 방정식이 regression에 더 적합할까?
Simple Linear Regression: Least Square
best fit은 실제 Y값과 예측된 Y값의 차이(ε)의 평균이 가장 작은 것을 의미한다.
Least Square = LS= Sigma( (Yi- Predict(Yi))^2 )= Sigma(ε^2)
(|ε|= |Yi- Predict(Yi)|= |실제값-예측값|)
따라서 우리는 Least Square값을 가장 작게 만드는 E(Yi)집합을 구성하는 방정식을 찾아야 한다.
=> 적절한 β0, β1을 찾는다
Predict(Y)= β0+ β1* Xi (단 Predict(Y)는 예측된 Y값)
에서 적절한 β0, β1은 다음 식을 이용해 구할 수 있다.
(유도과정은 생략한다)
β1= Cov(x,y)/Cov(x,x) (단 Cov는 공분산)
β0= E(y)- β1*E(x)= E(y)- E(x)* Cov(x,y)/Cov(x,x)
(단 E는 평균값)
β0은 y-intercept(y절편), β1은 slope(기울기)를 의미한다.
이제 이 값들을 회귀식에 대입해보면 선형회귀방정식은 다음과 같다.
Predict(Yi)= β0+ β1*xi
=E(y)- E(x)* Cov(x,y)/Cov(x,x) + xi* Cov(x,y)/Cov(x,x)
이 식을 이용해 특정 데이터셋에 대한 best fit을 만족하는 regression model을 구할 수 있다.
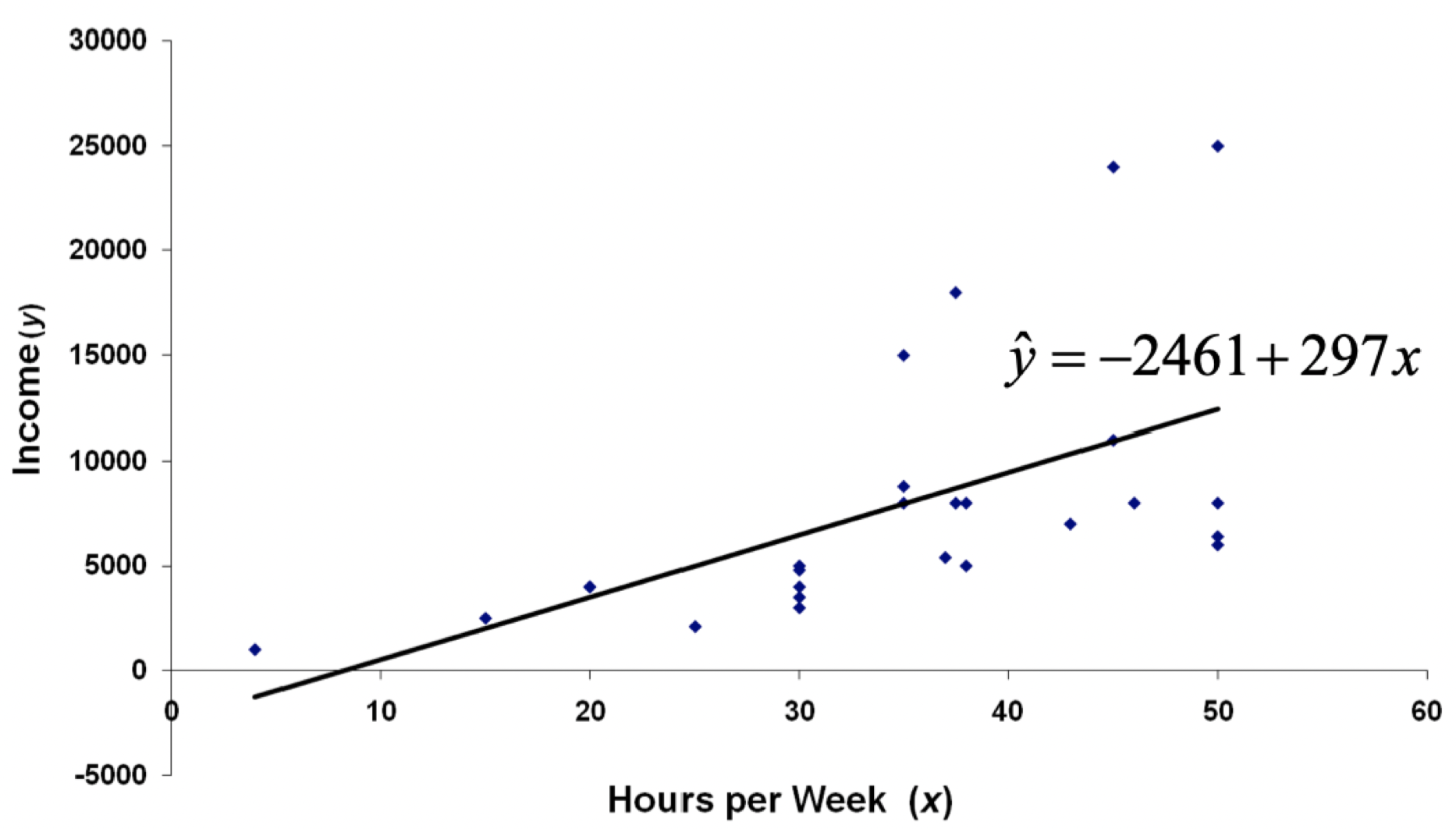
Multiple Linear Regression
독립변수의 갯수가 2개 이상인 경우 회귀방법이다.
Simple Linear Regression에서 변수의 갯수만 늘어났을 뿐 원리는 같다.
Predict(Yi)= β0+ β1*X1i+ β2*X2i+ ...
(단 Predict(Y)는 예측된 Y값이고, Xki에서 k는 k번째 독립변수, i는 i번째 데이터를 말한다)
'데이터사이언스' 카테고리의 다른 글
| [데이터사이언스] Gradient Desent (경사하강법) (0) | 2021.12.17 |
|---|---|
| [데이터사이언스] Regression Performance Estimation (회귀 성능 평가) (0) | 2021.10.22 |
| [데이터사이언스] 머신러닝 개요 (0) | 2021.10.22 |
| [데이터사이언스] 유사도(Similarity) (0) | 2021.10.22 |
| [데이터사이언스] 공분산(Covariance)과 상관관계(Correlation) (0) | 2021.10.21 |



